
两年前我写过一篇浅析C++ Atomic,那时我才刚开始接触原子操作不久。直到前不久在群聊里见到群友们又聊起原子操作与同步问题,我又意识到我对这方面的知识也处于一知半解的水平,于是才又下定决心重新研究了一遍,本文是我重新梳理相关知识的总结。
我会尽可能保证本文能够更通俗易懂一些,以方便大家能够把原子操作、内存序以及CPU设计等知识互相串联起来。如果你先前没有接触过原子操作,本文也可以作为入门教程供你了解相关的知识。
原子操作#
这一小节是写给零基础的小白看的,用于介绍什么是原子操作、为什么要用原子操作以及C++中如何使用原子操作。如果你已经很清楚为什么要使用原子操作,同时也十分熟悉C++原子操作的使用,那么你可以放心地略过这一小节。
虽然这一小节是写给小白看的,但我仍然希望你至少要了解操作系统的进程、线程等概念。如果你对于进程、线程、并行等概念也不熟悉,那么学习原子操作的知识想必对你来说有些过早了,还请先行了解一下并行和线程的概念。
什么是原子操作#
“原子(英文:Atomic)”一词源于古希腊语ἄτομος,意思是“不可分割的”。在编程中,我们所谓的原子操作和这个意思十分接近。所谓原子操作,就是不可中断的操作,即该操作必须“一口气完成”。
你可能觉得这东西十分不知所谓,比如下面的例子:
int i = 0;
i += 1;
显然,i只有两种状态嘛,要么i += 1没有执行,此时i为0;要么i += 1已经执行,此时i应为1。是的,在单线程环境下,这句话可以是成立的,但在多线程环境下则未必。先不要急着问为什么,请先看一下这段代码:
#include <cstdio>
#include <thread>
static int value = 0;
void increment() {
for (int i = 0; i < 100000; i++)
value += 1;
}
int main() {
std::thread t1{increment}; // Start thread t1 to execute increment().
std::thread t2{increment}; // Start thread t2 to execute increment().
t1.join(); // Wait for t1 to complete.
t2.join(); // Wait for t2 to complete.
std::printf("Value: %d\n", value);
}
在继续往下阅读之前,我建议你在自己的电脑上尝试运行一下这段代码。你可以多运行几次,看一下value的结果会是多少。
在上面的代码里,我开启了两个线程来执行increment()函数,所以最终value的结果理应是200000,但你实际得到的结果大概率不是200000,而是一些奇奇怪怪的数,这说明value += 1不是一个原子操作。探究发生这件事的原因之前,我们先铺垫一点CPU存储结构的知识。出于性能、成本等考量,现代计算机能存储数据的东西十分多且复杂,在这里我们只关心CPU能直接访问的存储结构,按照访问速度由快到慢列出:
- 寄存器(Register,在CPU上,访问速度最快,存储容量最小,CPU核心之间相互独立)
- 高速缓存
- 一级高速缓存(L1 Cache,在CPU上,CPU核心之间相互独立)
- 二级高速缓存(L2 Cache,在CPU上,通常CPU核心之间相互独立)
- 三级高速缓存(L3 Cache,在CPU上,通常由多个CPU核心共享)
- 内存
那么,当程序执行value += 1时,CPU可能是这么做的:
- 把
value从内存中读出来,放到寄存器rcx中;(我随便挑的寄存器,放在哪个寄存器里不重要) - 使寄存器
rcx中的值加一; - 将寄存器
rcx中的值写回value的地址。
所以,这一步实际上做了三件事情。在代码中,我开启了两个线程来执行increment()函数,这两个线程可能被分配给两个不同的CPU核心去执行。假设此时value的值为0,下面的执行顺序是有可能的:
| 时间 | CPU核心0 | CPU核心1 |
|---|---|---|
| 0 | 将value读取到rcx寄存器中,rcx = 0 | |
| 1 | rcx中的值加一,rcx = 1 | 将value读取到rcx寄存器中,rcx = 0 |
| 2 | 将rcx中的值写回value,value = 1 | rcx中的值加一,rcx = 1 |
| 3 | 将rcx中的值写回value,value = 1 |
是的,虽然value += 1在每个核心都被执行了一遍,但由于发生了上面的情况,所以value的最终结果却是1。我们称这种情况为数据竞争(Data Race)。
上面所述的数据竞争情况是一种极为简化的模型,旨在说明数据竞争问题的存在。实际代码由于编译器优化等原因,其执行顺序和CPU行为要复杂很多。
使用原子操作解决数据竞争#
C++的标准库本身为我们提供了原子操作,我们先使用原子操作改写一下上面的代码,如下所示:
#include <atomic>
#include <cstdio>
#include <thread>
static std::atomic<int> value{0};
void increment() {
for (int i = 0; i < 100000; i++)
value.fetch_add(1, std::memory_order_relaxed); // value += 1
}
int main() {
std::thread t1{increment};
std::thread t2{increment};
t1.join();
t2.join();
printf("Value: %d\n", value.load(std::memory_order_relaxed));
}
这份代码与之前的代码十分相似。你可以再运行一下试试,你会发现最终输出的结果始终是200000。让我们暂且忽略那个奇妙的std::memory_order_relaxed,我们会在后面讲解内存序的时候谈到它。代码中的value.fetch_add(1, ...)就是原子操作版本的value += 1。
正如在本节开头所说的那样,原子操作必须“一口气完成”,因此它不会被拆分为将变量读到寄存器中、修改寄存器、写回变量三步,而是使用一条CPU指令完成。现代CPU都会提供原子操作指令,用于实现各种各样的原子操作,而std::atomic相关的各种操作也会被编译器翻译成对应CPU的原子操作指令。关于std::atomic其他的使用方法,你可以参考cppreference.com。
CPU缓存一致性#
在讲内存序之前,我们需要先铺垫一点硬件相关的知识。
现代CPU为了兼顾性能与成本引入了高速缓存,而每个CPU核心拥有独立的L1缓存与L2缓存。假设value一开始为0,考虑下面这种情况:
| CPU核心0 | CPU核心1 |
|---|---|
将value的值更新为1,但此更新被直接写入到了CPU核心0的高速缓存中。 | |
因为缓存中没有,所以从内存中读取value的值。但因为CPU核心0没有直接写入内存,因此读取到了旧的value值0。 |
缓存的引入使得多核CPU的访存行为变得很像分布式系统。上面这种CPU核心1读取到错误value值的情况我们称之为缓存不一致。
我们先考虑一下CPU在单核的情况下会如何工作。读取操作会相对简单一点,CPU会先尝试从高速缓存中查找,如果高速缓存中没有找到,再去内存中查找对应的数据。写操作相对复杂一点,根据CPU同步方式的不同可以分为以下两类:
- 写回(Write Back):CPU核心会先尝试去修改高速缓存中的数据,如果高速缓存中存在,则直接在自己的缓存中修改数据,并标记该缓存行为已修改。
- 写通(Write Through):写入数据时,CPU核心会同步修改自己的缓存与内存。
除了同步方式,CPU处理缓存失效时的方式也分为以下两种:
- 按写分配:先将数据读入缓存,然后再更新数据。
- 不按写分配:总是直接将数据写回内存。
最简单的策略是写通且不按写分配,即CPU写入时总是同步更新自己的高速缓存与内存。由于L1和L2缓存对于其他核心是不可见的,因此CPU需要使用总线来广播核心的写操作以通知其他核心有数据被修改了。如果CPU每次写操作都需要通过总线来广播,那么多核CPU的性能会受到严重的影响。为此,CPU引入了缓存一致性协议(MESI),缓存总是处于以下四种状态之一:
| 状态 | 说明 |
|---|---|
| Modified(已修改) | 该缓存行刚刚被修改过,且保证不会出现在其他CPU核心的缓存中。此时该CPU核心为对应数据的唯一持有者。 |
| Exclusive(独占) | 与Modified类似。该缓存行的数据目前由该CPU核心独占,但因为没有被修改,因此与内存数据也一致。 |
| Shared(共享) | 该缓存行的内容与至少一个其他CPU所共享,因此CPU核心修改此缓存行时需要与其他CPU核心协商。 |
| Invalid(无效) | 该缓存行为无效行。 |
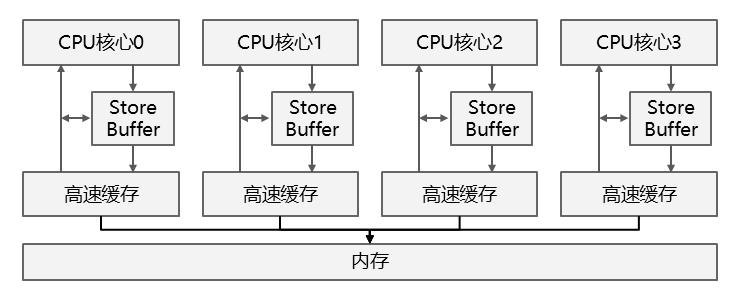
MESI协议被实现为一个状态机,可以保证多核系统共享数据的一致性。MESI状态机的实现不是我们的重点,因此略过不讲。我们关心的是,当一段数据在多个CPU核心中共享时,CPU核心在更新数据时需要通过总线发送Invalidate广播消息,等到其他CPU核心将缓存行置为Invalid状态后才能修改缓存数据,这是十分影响性能的。因此,CPU引入了Store Buffer和Invalidate Queue来提高性能。
Store Buffer#
在CPU和缓存之间引入Store Buffer以后,写操作就无需立即向其他CPU核心发送Invalidate消息了,而是先将写操作放入到Store Buffer中,然后立刻返回执行其他的操作,具体的写入和同步操作会由Store Buffer来执行。如果在Store Buffer中的数据写入缓存前就需要读取它,还需要直接从Store Buffer读取数据。因此引入了Store Buffer的CPU架构看起来像下面这样:
Invalidate Queue#
由于Store Buffer容量有限,如果Store Buffer发送Invalidate消息后,接受消息的CPU核心无法及时响应,则Store Buffer很快就会被写满,因此CPU还引入了Invalidate Queue。其他的CPU核心会将消息放入本核心的Invalidate Queue后立即确认Invalidate消息,而无需等待相关的缓存失效。引入了Invalidate Queue的CPU架构如下所示:
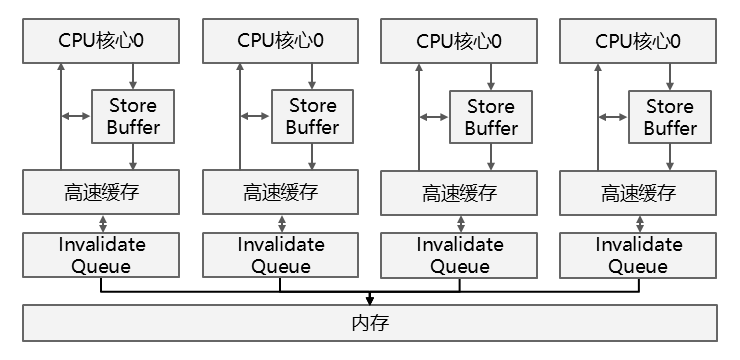
当CPU核心准备发送Invalidate消息时,CPU核心必须先查看自己的Invalidate Queue。如果自己的Invalidate Queue中存在对应未处理数据的Invalidate消息时,必须等待对应消息处理完才能发送。
Store Buffer与Invalidate Queue的引入会导致多核心数据同步时出现乱序的问题,让我们在内存屏障一节中详细讲述。
内存屏障#
要讲内存序就不得不讲内存屏障,因为内存序本质上就是内存屏障。内存屏障可以分为四类,分别解决不同的问题。
Store-Store屏障#
Store Buffer的引入会导致写入延后。考虑如下的代码,暂且忽略编译器重排和CPU指令重排,同时不考虑Invalidate Queue的存在:
int a = 0;
int b = 0;
// Thread 0 on CPU 0.
void foo() {
a = 1;
b = 1;
}
// Thread 1 on CPU 1.
void bar() {
while (b == 0)
continue;
assert(a == 1); // This may fail!
}
假设此时Cache的MESI状态如下:
a | b | |
|---|---|---|
| CPU0 | Shared | Modified |
| CPU1 | Shared | Invalid |
CPU0的操作如下:
- 将
a = 1的写入操作放入Store Buffer,此时缓存中的值还没有更新。 - 广播Invalidate
a。 - 修改
b = 1。因为b的状态是Modified,因此直接更新缓存中的值。
CPU1从CPU0的缓存处读到b为1,继续执行assert。但由于a = 1的写入指令还在Store Buffer中,因此CPU1读取到的a的值仍为0,从而产生错误的行为。这种后写入的数据被先更新的情况称为Store-Store乱序。Store-Store内存屏障可以解决这类问题,该内存屏障又叫做写屏障。
Load-Load屏障#
Invalidate Queue的引入会导致读取提前。这不是说Invalidate Queue会将读取指令提前,而是Invalidate Queue的引入会导致数据延迟更新,从而使得CPU读取到旧数据,看起来像是读取提前了。
还是上面的代码,让我们暂且忽略Store Buffer的存在。CPU0更新a的值以后,会将Invalidate a放入CPU1的Invalidate Queue中。如果CPU1读取a的值时,Invalidate Queue中的Invalidate a还没有执行,那么CPU1就会认为缓存中的a仍然处于Shared状态,从而读取到错误的a。对于CPU1来说,a的读取就像是被放在了b的读取之前,这种情况称为Load-Load乱序。Load-Load内存屏障可以解决这类问题,该内存屏障又叫做读屏障。
Load-Store屏障#
Load-Store与Store Buffer和Invalidate Queue无关,它可能发生在任何带有乱序执行的处理器上。比如:
int a = 0;
int b = 0;
// Thread 0 on CPU 0.
void foo() {
int temp0 = a;
b = 1;
}
// Thread 1 on CPU 0.
void bar() {
int temp1 = b;
a = 1;
}
在上面的例子中,temp0和temp1可能都为1。这看起来也许有些不可思议,但乱序执行确实允许这种情况发生。
对于CPU0来说,读取a和写入b = 1这两条指令之间没有依赖关系,因此CPU核心可以将b = 1放到temp0 = a之前去执行。
对于CPU1来说,读取b和写入a = 1这两条指令之间也没有依赖关系,因此CPU核心可以将a = 1放到temp1 = b之前去执行。
因此,整个CPU的执行顺序可能是这样的:
| 时间 | CPU0 | CPU1 |
|---|---|---|
| 0 | b = 1 | a = 1 |
| 1 | temp0 = a | temp1 = b |
然后,temp0和temp1的值就都为1了。
上面的例子中,写操作看起来就像是被提前到了读操作之前,这种情况称为Load-Store乱序。
Store-Load屏障#
读屏障只能解决Invalidate Queue的读提前问题,写屏障只能解决Store Buffer的写延迟问题,Store-Load屏障用于同时解决读提前与写延迟问题。
Store-Load屏障像是原子执行的读屏障+写屏障+其他一些操作(我不清楚具体有哪些操作,通常全屏障会同步所有的CPU核心,总之Store-Load屏障 != 读屏障 + 写屏障)。因为Store-Load屏障能够解决所有CPU重排问题,因此它又称为全屏障。
内存序(Memory Order)#
内存序是原子操作中十分令人迷惑的一个话题,cppreference.com试图脱离CPU架构来定义内存序,但内存序本身又和CPU架构关联十分密切,因此cppreference.com中关于内存序的定义十分诘屈聱牙。
总的来说,C++中的内存序有六种:
| 内存序 | 说明 |
|---|---|
memory_order_relaxed | 最宽松的内存序,相当于不执行内存屏障。 |
memory_order_consume | 类似于acquire内存序,我也没研究过。C++26已经宣布废除该内存序。 |
memory_order_acquire | 相当于读屏障,能够阻止该内存屏障之后的读取指令提前。 |
memory_order_release | 相当于写屏障,能够阻止该内存屏障之前的写指令延后。 |
memory_order_acq_rel | 相当于同时执行读屏障与写屏障。 |
memory_order_seq_cst | 相当于全屏障。 |
Acquire-Release模型#
通常我们使用内存序时都是为了在CPU核心之间同步数据。考虑一个简单的自旋锁的实现:
class SpinLock {
public:
SpinLock() : m_isLocked{false} {}
void lock() {
while (m_isLocked.exchange(true, std::memory_order_acquire))
__asm__ volatile("pause");
}
void unlock() {
m_isLocked.exchange(false, std::memory_order_release);
}
private:
std::atomic_bool m_isLocked;
};
lock函数会一直等待锁的释放,同时执行std::memory_order_acquire内存屏障。根据cppreference.com的描述,std::memory_order_acquire能够阻止之后的读取被提前,实际上就相当于读屏障。unlock函数释放锁的同时也执行了std::memory_order_release内存屏障,std::memory_order_release能够阻止之前的写入不会被延后,实际上就相当于写屏障。这二者保证了lock之后读取到的数据一定是最新的,且unlock时会刷新数据写入。
由此,通过Acquire-Release可以实现线程之间的数据同步,这也是无锁编程中最常见的同步方式。
Sequentially-Consistent内存序#
我们很少会见到memory_order_seq_cst,尤其是在原子变量上。memory_order_seq_cst通常用在多生产者多消费者(Multi-Producer Multi-Consumer,MPMC)数据结构上,考虑cppreference.com中的例子:
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
void write_x() {
x.store(true, std::memory_order_seq_cst);
}
void write_y() {
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst))
;
if (y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst))
;
if (x.load(std::memory_order_seq_cst))
++z;
}
int main() {
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
assert(z.load() != 0); // will never happen
}
在Acquire-Release模型中,上面的代码执行结束后,z.load() == 0是可能发生的,但使用Sequentially-Consistent内存序则不会。
假设我们使用的是Acquire-Release模型,那么我们看线程c的视角:
- 等待
x为true,此时说明write_x()已经执行结束。 - 读取
y,在线程c的视角中write_y()可能还没有执行,此时z为0。
我们再看线程d的视角:
- 等待
y为true,此时说明write_y()已经执行结束。 - 读取
x,在线程d的视角中write_x()可能还没有执行,此时z为0。
因此,z.load() == 0发生了。
在全局视角下看起来这很不可思议,但放在每个CPU核心的角度来看这是合理的——read_x_then_y从来没有和write_y进行过任何同步,同理read_y_then_x也没有和write_x进行过任何同步。因此MPMC场景下的同步通常需要使用memory_order_seq_cst。
X86与Total Store Ordering#
CPU在设计时会天然支持一定程度的一致性模型,X86架构的CPU采用的是Total Store Ordering(TSO)。
因为X86 CPU没有Invalidate Queue,因此访存时不需要读屏障。
因为X86 CPU的Store Buffer实现为严格的队列,保障了StoreStore顺序,因此也不需要写屏障。
因为X86 CPU没有任何处理器乱序会导致Load-Store问题,所以不需要考虑Load-Store屏障。
综上,对于X86架构的CPU来说,访存操作天然是std::memory_order_acq_rel的。这种内存一致性模型我们称为TSO。所以X86架构对于程序员而言十分友好。
volatile关键字#
一个典型错误是将C/C++中的volatile当作原子变量使用。Java中的volatile变量可以当作原子变量使用,但在C/C++中不可以。在C/C++中,volatile仅用于告诉编译器“嘿,不要优化这个变量的访问操作”,因此volatile变量不会被缓存在寄存器中。
volatile还能够一定程度阻止编译器的指令重排,但仅限于针对volatile变量的访问(或者说有副作用的访问操作),详见cppreference.com。
原则上volatile既不保证原子性也不保证内存序,但由于X86采用的是TSO内存模型,它天然保证了访存的原子性与内存序,因此很多人在误用了volatile的情况下也得到了正确的结果。但是,一旦迁移到ARM等弱内存模型的CPU上,这些代码就会产生错误的结果。
因此,不要将volatile变量当作原子变量使用。
编译器屏障#
volatile还有一个很有趣的用途,如下所示:
__asm__ volatile("" ::: "memory");
这行代码可以用作编译器屏障,它阻止编译器将这一行之前的代码重排到这一行之后,同时也阻止这一行之后的代码重排到这一行之前。原理也很简单,如上面所述,volatile能够阻止针对volatile变量的访问被编译器重排,而这一行内联汇编告诉了编译器“嘿,我访问了整个内存”(尽管这行代码实际上什么也没做),因此它阻止了所有的编译器重排。