
作为最新的异步计算框架,std::execution已经宣布进入C++26标准很久了。也许你在网络上见过不少介绍它如何使用的文章,比如如何组合任务,使用sync_wait进行同步等。但是,如果你抱有和我一样的疑问,你可能会发现std::execution远不止这么简单:
- 这套框架究竟是如何实现异步的?如果我要实现自己的异步抽象,我应该怎么做?
- 我要如何自定义我的
sender、receiver来实现我想要的功能? std::execution是如何与C++协程协同工作的?
本文会尝试站在使用者的角度,深入剖析std::execution的一些使用和实现细节,以供大家参考。如果读者没有了解过std::execution,本文也可以作为一篇进阶的入门指南,但我仍假设读者对基于回调函数的异步算法有一定的基础认知。
关于示例代码
由于大多数标准库尚未实现
std::execution,本文中所有的示例代码均使用stdexec作为参考实现。如果想要运行文中的示例代码,可以参考文章末尾的样例代码章节找到配置指引。
std::execution的工作流程#
在深入探讨细节之前,请先允许我介绍一下std::execution:
std::execution是一种标准C++异步模型,它基于三种关键抽象:scheduler、sender与receiver,以及一系列自定义异步算法。 ——P2300提案
没错,std::execution中的一切均围绕这三个概念展开。为了建立起直观的认识,我们先看一个简单的“Hello, world!”异步任务的例子:
int main() {
// pool is a context. A context manages some resources, like CPU, GPU, or something else.
exec::static_thread_pool pool;
// Acquire a scheduler from thread pool. Scheduler is like a handle to the context.
stdexec::scheduler auto sched = pool.get_scheduler();
// Create a sender from scheduler.
stdexec::sender auto begin = stdexec::schedule(sched);
stdexec::sender auto lazy_task = stdexec::then(begin, [] { std::println("Hello, world!"); });
// Busy waiting for the lazy task to be completed.
//
// stdexec::sync_wait is a sender consumer. It means that, this is the end of the lazy task. Usually, such sender
// consumers create a new receiver and simply pass them to executor::connect() to combine them with senders. We will
// talk about it in the future.
stdexec::sync_wait(lazy_task);
return 0;
}
在这段代码的开头出现了一个线程池pool。线程池pool不是scheduler,它是一个计算资源(Execution Resource)。紧接着,我们从pool中获取到了一个scheduler,也就是sched,sched本质上类似于指向pool的指针。随后,我们创建了两个sender,分别是begin与lazy_task。sender本质上是一个异步任务的“蓝图”,它会等到sync_wait的时候再执行。最后,我们使用sync_wait开启异步任务,并等待它执行完毕。上面的例子就是一个平平无奇的“你好,世界”。
在上面的例子中,我们使用stdexec::schedule(sched)创建了第一个sender。stdexec::schedule这个函数接受的参数只有一个scheduler,它能凭空创建sender,这种函数我们称之为sender工厂(sender factory)。随后,我们使用stdexec::then创建了第二个sender。stdexec::then接受一个sender并创建一个新的sender,这种函数我们称之为sender适配器(sender adapter)。最后,stdexec::sync_wait接受一个sender并不再产生新的sender,这种函数我们称之为sender消费者(sender consumer)。
为什么要引入scheduler,而不是直接使用计算资源本身?
因为计算资源不一定使用C++实现。尽管在上面的例子中,线程池是用C++实现的,但
std::execution的目标是实现一种通用的异步计算模式。只要设计得当,它还可以适配高性能计算集群、GPU、其他编程语言实现的计算资源等等。所以,std::execution引入了scheduler作为指向计算资源的handle。
也许你已经发现,上面的例子中没有出现receiver的身影,receiver的身影被sync_wait隐藏了。receiver的作用是接收异步任务的结果,它是异步任务链的终点。
让我们揭开sync_wait的面纱,看看它究竟做了什么:
template <sender_in<__env> _Sender>
auto apply_sender(_Sender &&sndr) const -> std::optional<...> {
// Prepare for something. Let's ignore it for now.
// Create operation state from sender and receiver.
auto __op = stdexec::connect(sndr, sync_wait_receiver);
// Start up the lazy task!
stdexec::start(__op);
// Busy wait.
__local_state.__loop_.run();
// Error handling and return value. Let's ignore it for now.
}
sync_wait函数主要做了三件事:
- 把sender与receiver给连接到一起。
connect会生成一个operation state。 - 启动这个operation state。在启动operation state后,这个异步任务就正式开始执行了。
- 等待任务完成。
stdexec::connect的作用是实例化异步任务,它表明我们不再修改sender,现在应该生成一个完整的、可执行的异步状态机,也就是operation state。
sync_wait_receiver是哪里来的?是
sync_wait自定义的receiver,它是在sync_wait函数中直接构造的。receiver用于接收异步任务的结果,我们会在自定义sender的章节谈到它。
sender和operation state都是异步任务,那它们有什么区别?
sender的作用是描述异步任务。打个比方,sender本身只是个“蓝图”。只有做出“成品”(operation state),我们才能使用它。
为什么不能直接运行sender呢?
刚刚我们提过,sender是可以修改的,比如使用
then进行组合。如果我们把异步状态都储存到sender中,那么sender会变得“很重”,在组合任务时会产生很多不必要的麻烦。框架本身会变得难以设计,组合sender也容易变得影响性能。
小结#
如果我们想用std::execution执行异步任务,那么我们只需要做以下几件事:
- 准备好计算资源;
- 使用sender描述自己的异步任务;
- 生成operation state,并启动异步任务。
在本小节中,我们提到了几个概念:
- scheduler: 指向计算资源的handle。
- sender:用于描述异步任务,可以使用sender factory创建,使用sender adapter进行组合,并使用sender consumer消费它。
- receiver:用于储存异步任务的结果,与sender组合可以产生operation state。
- operation state:异步状态机,储存了异步算法的所有状态,可以执行。
至此,你对std::execution的工作流程应该已经形成了一个完整的概念。接下来,我们将深入探讨如何自定义这些核心组件。
自定义sender#
要实现自定义的sender,只要实现connect方法即可。
connect方法接受一个receiver,这个receiver通常由下游sender或者consumer提供,并返回对应的operation state:
struct custom_sender {
using sender_concept = stdexec::sender_t;
template <std::receiver Receiver>
auto connect(Receiver &&rcvr) -> operation_state {
... // Construct operation state with receiver, and return it.
}
};
通常,自定义sender时我们也会实现对应的operation state,它是执行逻辑的载体。operation state必须实现start()方法,它是异步任务启动的唯一入口:
struct custom_operation_state {
using operation_state_concept = stdexec::operation_state_t;
auto start() & noexcept -> void {
...
}
};
receiver用于接受并处理异步算法的结果。通常,receiver包含set_value、set_error与set_stopped三个方法。如果异步任务正常结束,那么receiver的set_value会被调用;如果异步任务发生错误,那么set_error会被调用;如果异步任务被取消了,那么set_stopped会被调用:
struct custom_receiver {
using receiver_concept = stdexec::receiver_t;
// Called if async task completed successfully.
auto set_value(return_value) && noexcept -> void {
...
}
// Called if async task completed with error.
auto set_error(error_value) && noexcept -> void {
...
}
// Called if async task is cancelled.
auto set_stopped() && noexcept -> void {
...
}
};
Hello, world!#
现在,让我们抛开scheduler与sync_wait,实现一个最原始且最简单的sender,来看看它们是如何工作的。这个sender的作用仅仅是输出一个Hello, world:
template <stdexec::receiver R>
class hello_operation_state {
public:
using operation_state_concept = stdexec::operation_state_t;
hello_operation_state(R &&next) : m_rcvr{std::move(next)} {}
auto start() & noexcept -> void {
std::println("Hello, world!");
stdexec::set_value(std::move(m_rcvr));
}
private:
R m_rcvr;
};
struct hello_sender {
using sender_concept = stdexec::sender_t;
using completion_signatures = stdexec::completion_signatures<stdexec::set_value_t()>;
template <stdexec::receiver R>
requires(stdexec::receiver_of<R, completion_signatures>)
auto connect(R &&rcvr) const -> hello_operation_state<R> {
return hello_operation_state<R>{std::move(rcvr)};
}
};
struct my_receiver {
using receiver_concept = stdexec::receiver_t;
auto set_value() && noexcept -> void {
std::println("my_receiver set_value() is called!");
}
};
auto main() -> int {
stdexec::sender auto hello = hello_sender{};
stdexec::operation_state auto op = stdexec::connect(hello, my_receiver{});
stdexec::start(op);
return 0;
}
前面提到,sender的作用是描述异步任务,这项功能是通过自定义connect方法实现的。在上面的代码中,hello_sender实际上什么也没有,它的connect方法仅仅是创建并返回了我们自定义的operation state。
刚刚我们提到,异步算法的逻辑实际上是在operation state中实现的。本节的开头我们提过,hello_sender的任务就是输出一个Hello, world,所以我们在hello_operation_state::start中实现了它。但是,输出Hello, world之后,operation state又紧接着调用了receiver的set_value,这是为什么?
还记得吗,receiver用于接收与处理异步算法的结果。输出Hello, world之后,我们的算法顺利结束了。因此,我们需要告诉receiver该处理结果了。我们调用receiver的set_value,就是为了告诉它算法正常结束了。如果算法出现了错误,那么相应地,我们应该调用receiver的set_error,算法被终止也是类似的。
在继续阅读之前,我建议你动手尝试修改一下上面的例子,以加深自己对sender执行过程的理解。
- 不要手动创建operation state并start,使用
sync_wait执行上面的任务。你有没有发现什么?my_receiver对于hello_sender来说是必要的吗?- 假装异步任务执行错误,尝试调用receiver的
set_error。你可以把completion_signatures改成stdexec::set_value_t(), stdexec::set_error_t(std::exception_ptr)试试。- 使用
then或者其他的sender adapter把hello_sender与其他函数组合一下,然后看看执行效果。stdexec::connect函数返回的类型还是hello_operation_state吗?为什么程序仍然会输出“Hello, world!”呢?
then#
sender factory用于创建任务的起点,而sender adapter(比如then)则用于组合sender。接下来,我们来看一个更复杂一些的例子。
在前文中,我们已经使用了很多次then这个sender adapter了,它的作用很容易理解:当上一个sender的任务结束后,开始执行下一个函数,就像下面这样:
stdexec::then(begin, [] { std::println("Hello, world!"); });
那么,应当如何设计sender,receiver以及operation state以实现这个功能?
在上文中我们提过,当异步任务结束后,它应当调用receiver的set_value()以通知receiver处理任务结果。那么,只要我们在上一个sender完成时,拦截它的结果,执行then携带的函数,然后将结果传给下游的receiver即可:
template <stdexec::receiver Receiver, typename Func>
class then_receiver : public stdexec::receiver_adaptor<then_receiver<Receiver, Func>, Receiver> {
public:
template <typename... Args>
auto set_value(Args &&...args) && noexcept -> void {
// The previous sender would invoke `set_value` once it is done. Therefore, we could change the receiver's
// behavior by simply wrapping it.
try {
// auto result = m_func(args...);
// set_value(base(), result);
stdexec::set_value(std::move(*this).base(), std::invoke(std::move(m_func), std::forward<Args>(args)...));
} catch (...) {
stdexec::set_error(std::move(*this).base(), std::current_exception());
}
}
private:
Func m_func;
};
当上一个sender的任务结束后,只要它调用我们自定义的receiver,我们就能拦截sender的结果,并将它的结果传给then的自定义函数。要做到这一点,我们需要保证,上一个异步任务的sender应当与我们自定义的then_receiver进行connect,而非原本的receiver:
template <stdexec::sender PrevSender, typename Func>
class then_sender {
public:
using sender_concept = stdexec::sender_t;
then_sender(PrevSender s, Func f) : m_prev{std::move(s)}, m_func{std::move(f)} {}
template <stdexec::receiver Receiver>
auto connect(Receiver r) && -> stdexec::operation_state auto {
// Simply wrap the receiver and pass it to previous sender.
return stdexec::connect(std::move(m_prev), then_receiver<Receiver, Func>{std::move(r), std::move(m_func)});
}
private:
PrevSender m_prev;
Func m_func;
};
template <stdexec::sender S, typename F>
auto then(S s, F f) -> stdexec::sender auto {
return then_sender<S, F>{std::move(s), std::move(f)};
}
通过这种方式,我们就能够实现then的效果了。
注意
本小节中自定义
then的样例代码无法通过编译,因为缺少了一些细节。获取自定义then的completion_signature需要很复杂的模板元编程,而模板元编程并非本文的重点,因此略过我才不会承认是我懒得写了,哼。虽然stdexec提供的示例代码使用
get_completion_signatures函数提供了completion signature,但截至我撰写本文的时候,它仍然不能通过编译(sync_wait的时候会报错)。我不打算深究它的原因,如果读者有兴趣可以自行研究。
小结#
在本小节中,我们讨论了如何实现一个简单的sender factory以及sender adapter。通过这两个例子,我希望你能够了解sender与receiver的工作方式,以及如何实现自定义的sender。在下一节中,我们会讨论异步算法在std::execution中是如何实现的。
通过本章的两个例子不难看出,在具体的实现上,sender factory与sender adapter还是有较大不同的。由于sender factory是sender的起点,它通常需要自定义实现operation state,它的异步逻辑也在operation state中实现。而sender adapter由于需要接受其他sender的结果,它以receiver wrapper的方式实现自定义逻辑。
异步逻辑#
在了解了如何自定义sender后,我们终于可以开始讨论如何在std::execution中实现异步逻辑了。在展开讨论std::execution中的异步逻辑之前,先让我们回顾一下如何基于回调函数实现异步IO。下面的例子是Windows IOCP的例子:
struct overlapped : OVERLAPPED {
void (*on_complete)(overlapped *self, DWORD bytes, int error) noexcept;
};
while (!should_stop) {
if (GetQueuedCompletionStatus(iocp, &bytes, &key, &ovlp, INFINITE)) {
auto *object = static_cast<overlapped *>(ovlp);
object->on_complete(object, bytes, GetLastError());
}
}
下面的例子是Linux io_uring的例子:
class listener {
public:
virtual void on_complete(io_uring_cqe *cqe) noexcept = 0;
};
while (!should_stop) {
if (io_uring_wait_cqe(&ring, &cqe) == 0) {
auto *object = static_cast<listener *>(io_uring_cqe_get_data(&cqe));
object->on_complete(&cqe);
}
}
在基于回调函数的设计中,我们通常会启用一个事件循环。当事件发生后,就自动调用注册的回调函数处理事件。这种设计十分容易理解和上手,不过缺点也很明显——一旦异步逻辑变得复杂,回调函数就会变成地狱。
在高并发服务中,我们之所以需要采用这种设计,是因为IO事件的发生是不确定的。当我们试图recv数据的时候,对方的数据可能还没有到达。如果我们让CPU阻塞在这里,一直等到对方把数据发送过来才进行下一步的处理,那么CPU的利用效率会很低。一种更好的做法显然是我们把读事件注册给IOCP/io_uring,然后把CPU空出来去处理其他的事情。一旦对方把数据发送过来了,IOCP/io_uring会通知我们有数据可用了,那么程序再回来处理数据接收后的事情。
回到std::execution,我们处理异步逻辑的根本思想也是这样的,只不过注册事件与回调函数的处理要稍微复杂一点点。首先,让我们看一个IOCP的例子,这个例子是socket接收数据的例子:
struct operation_base : WSAOVERLAPPED {
auto (*on_complete)(operation_base *self, DWORD bytes, int error) noexcept -> void;
};
template <stdexec::receiver R>
class recv_operation : public operation_base {
public:
using operation_state_concept = stdexec::operation_state_t;
recv_operation(R &&receiver, SOCKET socket, void *buffer, std::size_t size)
: operation_base{},
m_receiver{std::move(receiver), socket, this},
m_socket{socket},
m_buffer{static_cast<ULONG>(size), static_cast<CHAR *>(buffer)} {
this->on_complete = &recv_operation::callback;
}
auto start() & noexcept -> void {
// Prepare for asynchronous recv operation. We assume that FILE_SKIP_COMPLETION_PORT_ON_SUCCESS is already set.
DWORD bytes = 0;
DWORD flags = 0;
int result = WSARecv(m_socket, &m_buffer, 1, &bytes, &flags, static_cast<WSAOVERLAPPED *>(this), nullptr);
if (result == SOCKET_ERROR) [[likely]] {
int error = WSAGetLastError();
if (error != WSA_IO_PENDING) { // Actual error.
stdexec::set_error(std::move(m_receiver), std::error_code{error, std::system_category()});
}
} else { // Completed immediately.
stdexec::set_value(static_cast<R &&>(m_receiver), bytes);
}
}
static auto callback(operation_base *op, DWORD bytes, int error) noexcept -> void {
recv_operation *self = static_cast<recv_operation *>(op);
// IO operation is cancelled. We should forward the stop request.
if (error == ERROR_OPERATION_ABORTED) {
stdexec::set_stopped(static_cast<R &&>(self->m_receiver));
return;
}
if (error == 0) {
stdexec::set_value(static_cast<R &&>(self->m_receiver), bytes);
} else {
stdexec::set_error(static_cast<R &&>(self->m_receiver), std::error_code{error, std::system_category()});
}
}
private:
R m_receiver;
SOCKET m_socket;
WSABUF m_buffer;
};
class recv_sender {
public:
using sender_concept = stdexec::sender_t;
using completion_signatures = stdexec::completion_signatures<stdexec::set_value_t(std::size_t),
stdexec::set_error_t(std::error_code),
stdexec::set_stopped_t()>;
recv_sender(SOCKET socket, void *buffer, std::size_t size) : m_socket{socket}, m_buffer{buffer}, m_size{size} {}
template <stdexec::receiver R>
requires(stdexec::receiver_of<R, void(std::size_t)>)
auto connect(R &&receiver) const -> recv_operation<R> {
return recv_operation<R>{std::move(receiver), m_socket, m_buffer, m_size};
}
private:
SOCKET m_socket;
void *m_buffer;
std::size_t m_size;
};
在这个例子中,我是按照sender factory的方式设计的recv_sender。在上文中我们提到过,std::execution通过调用operation state的start来启动异步算法。所以,我们在recv_operation::start中注册IO事件。
但是,IO事件并不一定会立刻完成。所以,与自定义sender一节中不同的是,我们不在start中直接调用receiver的set_value,而是在注册的回调函数中调用它。当IOCP通知IO事件完成的时候,我们在事件循环中调用operation_base::on_complete(),而回调函数会根据IO的结果决定执行receiver的set_value,set_error还是set_stopped。通过这样的方式,我们就实现了sender与异步算法的结合。
明明很少有人用Windows做服务器,为什么要举IOCP的例子?
其实我有一个绝妙的点子能用sender实现epoll或者io_uring的异步IO,但这里空间太小了,写不下,所以就留给读者自己实现咯。
小结#
在本节中,我们实现了一个简单的异步socket recv逻辑。通过这个例子,我希望你能明白sender是如何与异步逻辑相结合的。
在我看来,std::execution并没有脱离回调函数的本质,只不过它带来了一些“约束”。当我们遵守这些“约束”来编写回调函数的时候,我们能够使代码的逻辑更加清晰且易于组合,实际上这就是**结构化并发(Structured Concurrency)**带来的好处。在结构化并发章节,我们会简单地讨论一下结构化并发的话题。
Scheduler#
尽管确实存在inline_scheduler这种奇葩scheduler不依赖于计算资源,但在实际应用中,大部分的scheduler仍然是依赖于计算资源的,否则我们也没必要编写异步逻辑了。计算资源都有自己特定的实现方式,比如io_context多采用事件循环,计算资源的实现方式不在本文的讨论范围内。但是,关于scheduler,我们发现只需要使用stdexec::schedule(sched)创建一个sender,我们就能把异步计算过程给丢到计算资源里,这究竟是怎么做到的?
回想我们如何使用线程池的 scheduler:
stdexec::sender auto begin = stdexec::schedule(sched);
刚刚我们提到,stdexec::schedule(sched)是一个sender factory,那么很有可能,打包异步算法的实现就在operation state的start方法里。让我们看看exec::static_thread_pool中,它是如何实现的。为了便于理解,下面的代码经过了高度简化:
template <class ReceiverId>
class _static_thread_pool::_opstate<ReceiverId>::__t : public task_base {
// This is constructor.
explicit __t(...) {
this->execute_ = [](...) {
stdexec::set_value(static_cast<Receiver&&>(op.rcvr_));
};
}
void enqueue_(task_base* op) const {
pool_.enqueue(*queue_, op, thread_index_);
}
public:
void start() & noexcept {
enqueue_(this);
}
};
不难发现,operation state把receiver存了起来,并向线程池提交了一个多态任务。当线程池调度到这个任务的时候,它就会调用receiver的set_value方法,进而启动后续的异步算法。本质上,这就是把任务打包成std::function<void()>并提交给线程池,只不过stdexec的实现避免了把receiver移来移去,避免了std::function<void()>潜在的申请堆内存的开销,以及使用了其他的一些优化(比如MPSC队列)。
相较于
static_thread_pool还需要打包任务,inline_scheduler就简单多了。inline_scheduler只需要在operation state的start中调用receiver的set_value方法就能实现它的功能。
小结#
参考线程池scheduler的实现方式,读者应该不难想象其他各种scheduler是如何实现的,比如CUDA。相较于协程,std::execution的一大优点便是它几乎不需要动态内存申请,这也是它高性能的原因之一。在我们上面所有的例子中,包括static_thread_pool的scheduler,没有发生任何一次堆内存分配。但代价就是receiver会变成模板套模板,而且编译速度会变得很慢。
协程#
std::execution是支持与协程配合使用的,不过在各大文章中貌似鲜有提及。虽然std::execution已经能够很好地支持结构化并发,但有些控制逻辑通过协程编写仍然更易于阅读和维护,比如循环逻辑。下面是一个简单的使用协程的例子:
template <stdexec::scheduler Scheduler>
auto some_func(Scheduler sched) -> exec::task<void> {
co_await stdexec::schedule(sched);
std::println("This is coroutine function.");
co_return;
}
auto main() -> int {
exec::static_thread_pool pool;
stdexec::scheduler auto sched = pool.get_scheduler();
stdexec::sync_wait(some_func(sched));
return 0;
}
协程是可以与std::execution框架一起使用的。在实际应用中,协程的awaitable都可以作为std::execution的sender使用:
template <stdexec::scheduler Scheduler>
auto some_func(Scheduler sched) -> exec::task<int> {
co_await stdexec::schedule(sched);
std::println("This is coroutine function.");
co_return 1;
}
auto some_func1(int value) -> std::string {
std::println("Received {} from some_func.", value);
return "some_func1 string";
}
auto some_func2(std::string value) -> void {
std::println("Received \"{}\" from some_func1.", value);
}
auto main() -> int {
exec::static_thread_pool pool;
stdexec::scheduler auto sched = pool.get_scheduler();
stdexec::sender auto task = some_func(sched) | stdexec::then(some_func1) | stdexec::then(some_func2);
stdexec::sync_wait(std::move(task));
return 0;
}
协程的awaitable之所以可以全部当做sender使用,是因为协程awaitable只支持sender功能的子集。awaitable最多只能有一个返回值,这就相当于调用set_value。如果awaitable抛出异常,这就相当于调用set_error。但无论如何,协程是不可中断的。
同样地,sender也可以当做awaitable使用。下面这个例子来自Working with Asynchrony Generically: A Tour of C++ Executors:
// This is a coroutine:
unifex::task<int> read_socket_async(socket, span<char, 1024>);
unifex::task<void> concurrent_read_async(socket s1, socket s2) {
char buff1[1024];
char buff2[1024];
auto [cbytes1, cbytes2] =
co_await std::execution::when_all(
read_socket_async(s1, buff1),
read_socket_async(s2, buff2)
) | into_tuple();
/*...*/
}
但是,sender除了正常返回,它还可能发生错误(set_error)或者被终止(set_stopped)。如果发生了错误,那么sender会抛出异常。如果sender被终止了,由于协程并不支持set_stopped,这时候整个协程栈都会被回滚并销毁,就像抛出了一个不可被捕获的异常那样(sender被终止并非抛出异常,只是行为像,catch (...)并不能阻止这一过程)。
当然,也有办法可以阻止这一情况。std::execution提供了stopped_as_optional()和stopped_as_error()。如果我们把sender用它们包起来,那么sender被终止是就会返回空(stopped_as_optional())或者抛出异常(stopped_as_error())。
TCP Server#
协程的加入使std::execution框架具备了更大的灵活性。例如,我们可以像下面这样实现一个TCP Server:
template <stdexec::scheduler Scheduler>
auto listener(Scheduler sched, exec::async_scope &scope, tcp_listener srv) -> exec::task<void> {
co_await stdexec::schedule(sched);
auto stop_token = scope.get_stop_token();
while (!stop_token.stop_requested()) {
tcp_stream stream = co_await srv.accept();
scope.spawn(stdexec::schedule(sched) | handle_connection(std::move(stream)));
}
}
auto main() -> int {
io_context context;
exec::async_scope scope;
// Create tcp_listener...
stdexec::sync_wait(listener(stdexec::schedule(sched), scope, std::move(srv)));
return 0;
}
上面只是一段伪代码,不过我们能够从中看出结合std::execution与协程的思路。我们在协程中实现比较复杂的控制逻辑,比如while循环等,然后使用sender组合相对简单且性能敏感的逻辑,以充分利用二者的优点。
async_scope是哪里冒出来的?早些时候,要非阻塞地分离一个sender需要使用
start_detached()。但在晚些版本的提案中,start_detached()出于不安全的原因所以被废弃了,因为start_detached()把任务分离出去以后就完全不管了。async_scope会在析构的时候等待提交的所有异步任务完成,这意味着所有异步任务的析构函数能够被顺利执行,从而避免一些潜在的问题。
小结#
在本节中,我介绍了如何将sender与协程结合使用。恰当的设计能够使我们的程序结合二者的优点,兼顾可维护性与高性能。
C++20引入的协程需要使用new来创建协程栈帧(协程状态),过于频繁地申请内存可能会影响性能。尽管C++标准允许编译器合并嵌套调用的协程栈,但目前所有的编译器对这一优化的支持只能说是聊胜于无。这样看来,sender仍然是解决这一问题的更好的方案。
结构化并发#
我们经常见到,C++一提结构化并发那就是std::execution,但似乎鲜有人讲清楚结构化并发到底是个什么东西,直到我看到Working with Asynchrony Generically: A Tour of C++ Executors (Part 2/2)中Eric Niebler对结构化并发的讲解。
要理解什么是结构化并发,首先要搞明白什么是结构化。我们看下面这个例子,图片来自Working with Asynchrony Generically: A Tour of C++ Executors (Part 2/2):
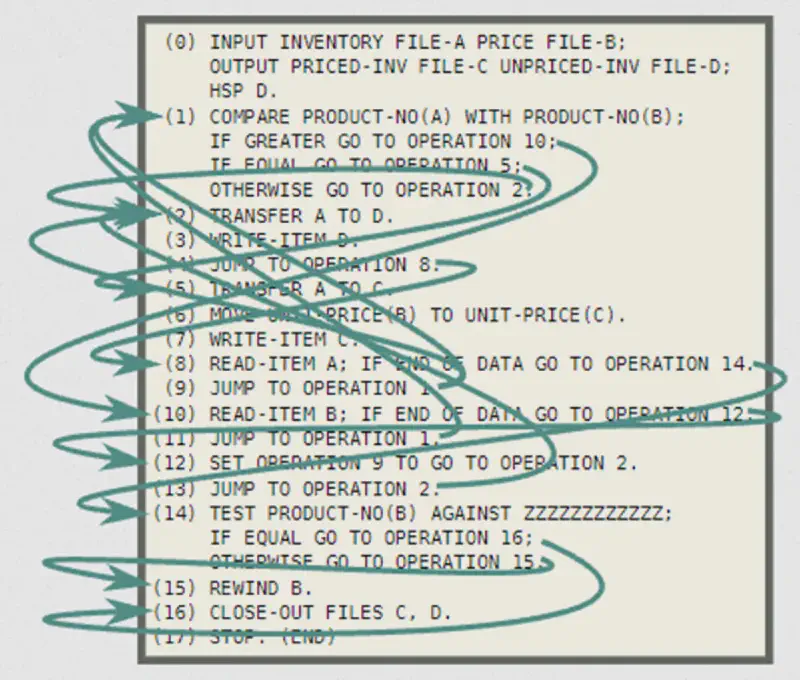
在这份代码中,goto满天飞,整个程序的逻辑分布在代码的各个地方,这就是非结构化的代码。那么结构化的代码应该是什么样子?看下面这个示例:
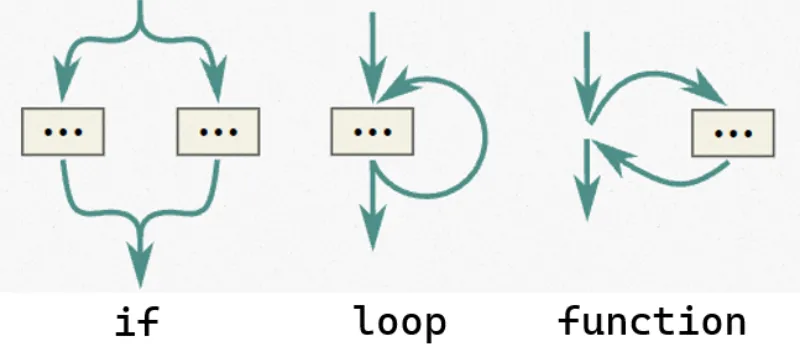
结构化的代码它的调用入口与调用出口是固定的,也正因此它的代码结构更清晰。
基于回调函数的状态机是典型的非结构化代码。虽然我们的入口总是回调函数,但整个状态机的维护需要我们手动来处理,任务的开始和结束点不清晰。std::execution使用sender adapter将可以进行的操作固定了下来,我们总是使用sender adapter组合我们的代码逻辑,也因此我们称std::execution是结构化并发。
其实协程也是一种结构化并发,就像下面这样。它与结构化的代码也是一样的:
auto result = co_await stream.recv(buffer);
if (result.has_value()) {
...
}
更进一步的细节,如果读者感兴趣的话,可以去观看CppCon原视频。
总结#
本文从一个最简单的“你好,世界”开始,深入讨论了std::execution的整个工作流程。通过自定义sender factory和sender adapter,本文展示了如何利用operation state与receiver来构建和启动异步任务。随后,本文通过异步IO的例子展示了如何在std::execution中应用异步算法,并在最后讨论了scheduler的实现机制以及std::execution与C++协程的融合方法。
最后,感谢各位读者能够读到这里,也希望本文对各位读者使用std::execution能够有所帮助。
推荐阅读#
P2300R10提案的开头给出了std::execution在各个领域的例子,各位读者可以看一下。在充分理解本文的基础上,相信大家对std::execution能有更深刻的理解。
Working with Asynchrony Generically: A Tour of C++ Executors系列对std::execution的使用有比较具体的讲解。不过由于视频比较早,一些API与现在的std::execution并不完全一致,观看视频时请注意甄别。
样例代码#
你可以使用ModernCppStarter快速创建一个样例工程。ModernCppStarter自带了CPM,你可以使用CPM快速添加stdexec依赖:
include(cmake/CPM.cmake)
CPMAddPackage(
NAME stdexec
GIT_REPOSITORY https://github.com/NVIDIA/stdexec.git
GIT_TAG main
OPTIONS
"STDEXEC_BUILD_TESTS OFF"
"STDEXEC_ENABLE_EXTRA_TYPE_CHECKING OFF"
"STDEXEC_ENABLE_CUDA OFF"
"STDEXEC_ENABLE_TBB OFF"
"STDEXEC_ENABLE_TASKFLOW OFF"
"STDEXEC_ENABLE_ASIO OFF"
"STDEXEC_ENABLE_IO_URING OFF"
"STDEXEC_BUILD_EXAMPLES OFF"
"STDEXEC_BUILD_TESTS OFF"
)
target_link_libraries(your-project PRIVATE stdexec)
参考资料#
- P2300R10:
std::execution - P3149R8:
async_scope– Creating scopes for non-sequential concurrency - P3552R3: Add a Coroutine Task Type
- Working with Asynchrony Generically: A Tour of C++ Executors (Part 1/2)
- Working with Asynchrony Generically: A Tour of C++ Executors (Part 2/2)
- stdexec
文章配图#
文章配图是巧克甜恋中雪村千绘莉的官方CG。